Transformer
总体架构
代码:harvardnlp/annotated-transformer

Transformer的基本结构,通过模型结构图可看出Transformer是由Encoder与Decoder构成:
左边的部分是编码器Encoder,右边的部分是解码器Decoder,根据不同的任务需要,使用对应的部分,一般编码器部分常用于文本编码分类,解码器部分用于语言模型生成,Encoder和Decoder都包含6个block层,编码器和解码器并不是简单的串联关系。
编码器Encoder
每个编码器由两层结构组成:
- 第一层包括:多头自注意力层, 规范化层(LayerNorm)、残差连接。
- 第二层包括:前馈全连接层、规范化层(LayerNorm)、残差连接。
编码器Encoder 由6个相同层block组成,每一层由相同的两部分组成:一个多头注意力层和一个Feed Forward层。这两个部分后面都进行残差连接和LayerNorm归一化 LayerNorm(x +Sublayer(x))。Feed Forward层其实就是简单的MLP层,由两个线性层组成,中间用ReLU函数进行激活。
解码器Decoder
每个解码器由三层结构组成:
- 第一层包括:多头自注意力层(Masked Multi-Head Attention)、规范化层(LayerNorm)、残差连接。
- 第二层包含:多头注意力层(Multi-Head Attention)、规范化层(LayerNorm)、残差连接。
- 第三层包含:前馈全连接层、规范化层(LayerNorm)、残差连接。
解码器Decoder 也是由6个相同层组成,每一层由相同的三部分组成:一个带掩码的多头注意力层(Masked Multi-Head Attention)、一个多头交叉注意力层(Multi-Head Cross Attention)和一个MLP层。与编码器一样都在各部分后添加残差和LayerNorm归一化,不同的是在多头注意力层中输入的是由编码器输出的key、value和经过带掩码的多头注意力层输出的query。
Masked Multi-Head Attention:
Masked Multi-Head Attention是带attention mask的MHA(Multi-Head Attention),Encoder中用的是不带attention mask的MHA,Encoder输入src只进行了padding mask,Decoder同时使用了padding mask和attention mask。
Q: Transformer 的 Encoder、Decoder 和 GPT 的架构有什么区别?
Decoder 相较于 Encoder 多了掩码机制和交叉注意力,实际上真正区分二者的是自注意力中的掩码机制,防止模型在生成时看到未来的词。交叉注意力也被称为编码器-解码器注意力(Encoder-Decoder Attention)。
输入输出层
模型输入: Transformer输入向量X由词向量Embedding和位置向量Positional Encoding相加得到。
Transformer使用的是正余弦位置编码。位置编码通过使用不同频率的正弦、余弦函数生成,位置编码公式如下:
其中:
- i是位置向量的下标,2i和2i+1表示奇偶性,它的取值范围是[0,…,d_model / 2];
- pos表示数据在序列中的绝对位置,pos=0,1,2…,max_len-1;
- d_{model}表示位置向量的维度(transformer论文中设置的是512维)。
参考文章:Transformer学习笔记一:Positional Encoding(位置编码)
公式实现:
class PositionalEncoding(nn.Module): |
其中div_term没有直接进行幂运算,而是先转换为了等价的指数+对数运算,这样做是为了确保数值稳定性和计算效率:
- 直接使用幂运算可能会导致数值上溢或下溢。当d_model较大时,10000.0 ** (-i / d_model)中的幂可能会变得非常小,以至于在数值计算中产生下溢。通过将其转换为指数和对数运算,可以避免这种情况,因为这样可以在计算过程中保持更好的数值范围;
- 在许多计算设备和库中,指数和对数运算的实现通常比幂运算更快。这主要是因为指数和对数运算在底层硬件和软件中有特定的优化实现,而幂运算通常需要计算更多的中间值。
div_term公式如下:
其中的中括号对应的是一个从 0 到 d_{model} - 1 的等差数列(步长为 2),设为i
且上述公式与这个公式是等价的:
可以通过下面公式求证(两边同时ln结果相等):
模型输出: Transformer中输出层由一层线性层Linear和一层Softmax组成。
参考文章:https://www.cnblogs.com/tian777/p/17917392.html
自注意力机制
核心公式:
Q 代表query,代表要查询的信息,后续会去和每个K进行匹配。
K 代表key, 代表索引,也就是被查询的向量, 后续会被每个Q匹配。
V 代表value,代表查询到的值,Q和K匹配的过程可以理解成计算两者的相关性,相关性越大对应V的权重也就越大。
代码实现:
def attention(query, key, value, mask=None, dropout=None): |
多头注意力机制:

代码实现:
class MultiHeadedAttention(nn.Module): |
Feed Forward层
Feed Forward 层是一个两层的全连接层,第一层的激活函数为 ReLU,第二层不使用激活函数。
BERT
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
源码(PyTorch版本):codertimo/BERT-pytorch
模型配置
Google 论文中提出了Base和Large两种BERT模型。
| 模型 | Layers | Hidden Size | Attention Head | 参数数量 |
|---|---|---|---|---|
| Base | 12 | 768 | 12 | 110M |
| Large | 24 | 1024 | 16 | 340M |
模型结构
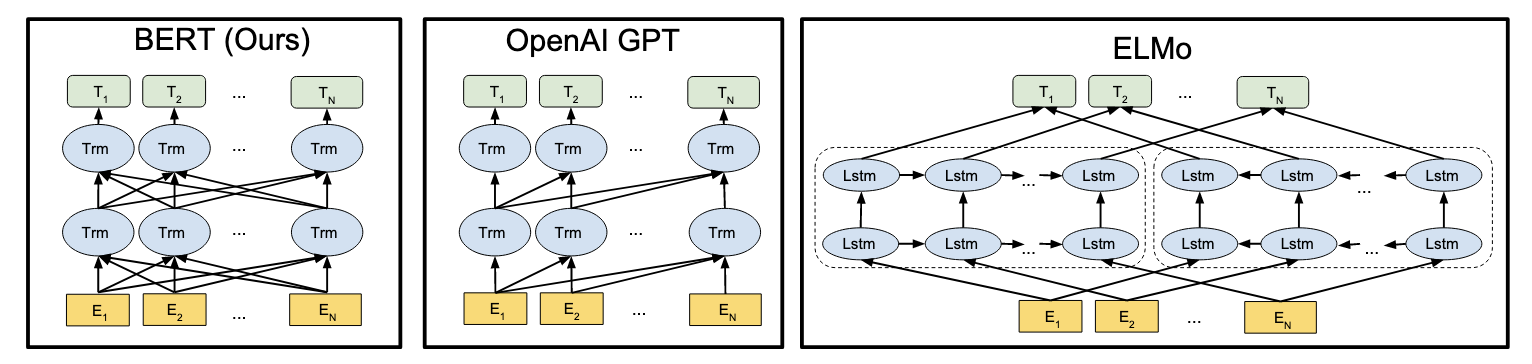
BERT只是使用了Transformer中的Encoder部分,没有Decoder部分,因此相较于Transformer中的两种mask(key padding mask和attention mask),BERT中只有key padding mask,也就是忽略掉padding部分的信息,而在Transformer的解码阶段还需要忽略掉当前位置之后的信息所以还要使用attention mask。
💡 BERT采用和Transformer相同的Post-Norm结构。 |
输入表示
针对不同的任务,BERT模型的输入可以是单句或者句对。对于每一个输入的Token,它的表征由其对应的词表征(Token Embedding)、段表征(Segment Embedding)和位置表征(Position Embedding)相加产生,如下图所示:

- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务,对于英文模型,使用了Wordpiece模型来产生Subword从而减小词表规模,对于中文模型,直接训练基于字的模型。
- Segment Embeddings用来区别两种句子,因为预训练不仅做LM还要做以两个句子为输入的分类任务,为区别两个句子,用一个特殊标记符[SEP]进行分隔,对于单句输入,只有一种Segment Embedding,对于句对输入,会有两种Segment Embedding。
- Position Embeddings和Transformer的位置编码不同,不是三角函数而是学习出来的。
预训练目标
BERT预训练过程包含两个不同的预训练任务,分别是Masked Language Model和Next Sentence Prediction任务。
Masked Language Model(MLM)
通过随机掩盖一些词(替换为统一标记符[MASK]),然后预测这些被遮盖的词来训练双向语言模型,并且使每个词的表征参考上下文信息。
这样做会产生两个缺点:(1)会造成预训练和微调时的不一致,因为在微调时[MASK]总是不可见的;(2)由于每个Batch中只有15%的词会被预测,因此模型的收敛速度比起单向的语言模型会慢,训练花费的时间会更长。对于第一个缺点的解决办法是,把80%需要被替换成[MASK]的词进行替换,10%的随机替换为其他词,10%保留原词。由于Transformer Encoder并不知道哪个词需要被预测,哪个词是被随机替换的,这样就强迫每个词的表达需要参照上下文信息。对于第二个缺点目前没有有效的解决办法,但是从提升收益的角度来看,付出的代价是值得的。
Next Sentence Prediction(NSP)
为了训练一个理解句子间关系的模型,引入一个下一句预测任务。这一任务的训练语料可以从语料库中抽取句子对包括两个句子A和B来进行生成,其中50%的概率B是A的下一个句子,50%的概率B是语料中的一个随机句子。NSP任务预测B是否是A的下一句。NSP的目的是获取句子间的信息,这点是语言模型无法直接捕捉的。
Google的论文结果表明,这个简单的任务对问答和自然语言推理任务十分有益,但是后续一些新的研究[15]发现,去掉NSP任务之后模型效果没有下降甚至还有提升。我们在预训练过程中也发现NSP任务的准确率经过1-2个Epoch训练后就能达到98%-99%,去掉NSP任务之后对模型效果并不会有太大的影响。
参考文章:
https://tech.meituan.com/2019/11/14/nlp-bert-practice.html
https://zhuanlan.zhihu.com/p/46652512
https://www.zhihu.com/question/404452350/answer/2217828686
GPT
论文:
源码(PyTorch版本):
-
https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt2/modeling_gpt2.py
-
https://github.com/graykode/gpt-2-Pytorch/blob/master/GPT2/model.py
模型细节
模型架构

💡 GPT 保留了 Decoder 的Masked Multi-Head Attention 层和 Feed Forward 层,并扩大了网络的规模。 |
Text & Position Embed
- Text Embed:将输入的词转化为可训练的嵌入向量。
- Position Embed:使用可学习的位置信息嵌入,这里和 Transformer 默认的正余弦位置编码不同,但 Transformer 论文的 Table 3 (E) 中有对比二者的性能差异,所以并非一个新的方法。
Transformer Block
- Masked Multi-Head Self-Attention:掩码多头自注意力机制,在生成任务中,每次预测一个词时,当前词只能看到左侧的上下文信息,未来的词和预测的词都会被掩盖。对应于 Transformer 架构中 Masked Multi-Head Attention。
- Add & Norm:Layer Norm (LN) + 残差连接 (+)。
- Feed-Forward:前馈网络 (Feed-Forward Network, FFN)。
- Add & Norm:Layer Norm (LN) + 残差连接 (+)。
Prediction 和 Task Classifier
- Text Prediction:用于生成任务,预测下一个词。
- Task Classifier:用于分类任务,如情感分析或文本蕴含任务。
💡 左侧的 12x 表示堆叠了12层 transformer_block。 |
无监督预训练
给定一个无标注样本库的token序列集合 U={u1,u2…un} ,语言模型的目标就是最大化下面的似然值。也就是通过前面的tokens,预测下一个token。
其中,k是滑动窗口的大小,P是条件概率。模型参数使用SGD进行优化。
GPT-1使用了12层Transformer decoder结构。输入包括文本向量和位置向量。
其中,U表示token的文本向量, We 表示token embedding矩阵, Wp 表示位置向量矩阵。每个token会通过transformer block被编码,最后再经过一个线性层+softmax,得到下一个token的预测分布。
有监督微调
得到无监督的预训练模型后,将得到的参数值直接应用于有监督任务中。对于一个有标签的数据集C,每个实例有m个输入tokens: {x1,…xm} 。将这些tokens输入到预训练模型中,得到transformer block的输出向量 h ,再经过一个全连接+softmax,得到预测结果y:
有监督学习的目标即最大化上述概率:
值得一提的是,作者发现,把预训练目标作为辅助目标加入下游任务loss中,将会提高有监督模型的泛化性能,并加速收敛。因此,有监督任务的最终优化目标是:
GPT-2
GPT-1 和 GPT-2 的区别:
- GPT-2相比GPT-1拥有更大的数据集、更大的模型参数。
- GPT-1:Post-Norm,层归一化放置在残差连接之后。
- GPT-2:Pre-Norm,层归一化放置在残差连接之前。
Post-Norm/Pre-Norm:
# Post-Norm |
GPT-3
GPT-3 :相比GPT-1和GPT-2拥有更大的数据集和更大的模型。
参考文章: